커서를 직접 정의해 사용하는 explicit 커서 방식은
pl/sql문에서 select 작업을 수행시키는 데 네트워크 트래픽을 줄여줄 수 있다.
implicit 커서의 경우 하나보다 많은 row가 반환되었을 경우
exception을 발생시켜야 하므로 수행성능을 저하시킬 수 있다.
exception 처리를 하기 위해서는 커서로부터 하나의 row를 패치해 온 다음
Too_Many_Rows exception의 발생 여부를 확인하기 위해서
두번째 row에 대한 패치를 시도해야만 한다.
- oracle developer/2000 programmer's guide. bnc
implicit 커서는 select - into - 문을 사용했을 때 사용되는 커서임.
PL/SQL2007. 5. 4. 16:04
SQL2007. 4. 18. 15:18
참고 : Oracle Magazine
SELECT b.department_name, a.job_id, sum(a.salary) sal, count(a.employee_id) emp_count
FROM employees a, departments b
WHERE a.department_id = b.department_id
GROUP BY b.department_name, a.job_id;
위 쿼리를 실행했을 때
9i와 10g의 결과가 서로 다르게 나타난다.
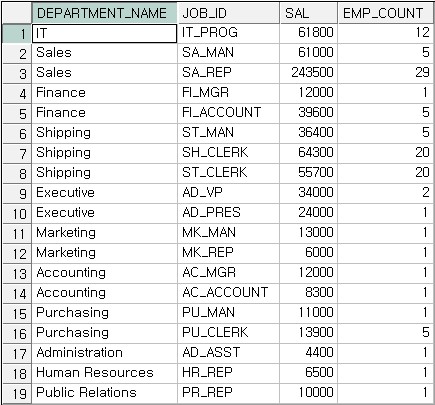
ORACLE 데이터베이스 릴리스 간에는 중요한 GROUP BY 방식의 차이가 있다. 이러한 차이는 GROUP BY가 두 개 이상의 Parameter를 받을 때 결과로써 더욱 확연하게 드러나는 데, 각 ORACLE 데이터베이스 릴리스 별로 GROUP BY 방식은 아래처럼 설명할 수 있다.
Oracle 8i Database : Character Sort GROUP BY
Oracle 9i Database : Binary Sort GROUP BY
Oracle 10g Database : Hash based GROUP BY
캐릭터 소트와 바이너리 소트가 호환될 수 있는 것은 US7ASCII 문자 셋이 처리될 때 뿐일 것이다. ORACLE 9i의 GROUP BY와 같이 내부적으로 바이너리 소트 매커니즘을 사용할 때에는 그룹된 Parameter가 어떤 선호 인덱스의 영향을 받냐에 따라서도 Parameter 간의 우선 순위가 역전될 수 있다.
SELECT b.department_name, a.job_id, sum(a.salary) sal, count(a.employee_id) emp_count
FROM employees a, departments b
WHERE a.department_id = b.department_id
GROUP BY b.department_name, a.job_id;
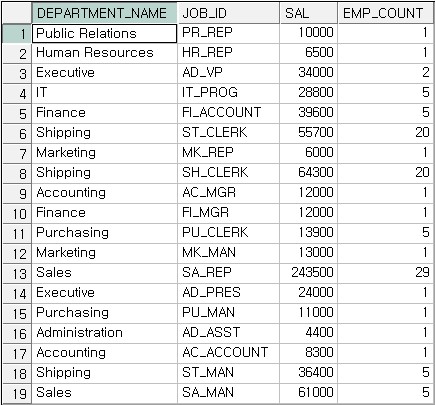
위 쿼리를 실행했을 때
9i와 10g의 결과가 서로 다르게 나타난다.
9i에서의 쿼리 결과
10g에서의 쿼리 결과
ORACLE 데이터베이스 릴리스 간에는 중요한 GROUP BY 방식의 차이가 있다. 이러한 차이는 GROUP BY가 두 개 이상의 Parameter를 받을 때 결과로써 더욱 확연하게 드러나는 데, 각 ORACLE 데이터베이스 릴리스 별로 GROUP BY 방식은 아래처럼 설명할 수 있다.
Oracle 8i Database : Character Sort GROUP BY
Oracle 9i Database : Binary Sort GROUP BY
Oracle 10g Database : Hash based GROUP BY
캐릭터 소트와 바이너리 소트가 호환될 수 있는 것은 US7ASCII 문자 셋이 처리될 때 뿐일 것이다. ORACLE 9i의 GROUP BY와 같이 내부적으로 바이너리 소트 매커니즘을 사용할 때에는 그룹된 Parameter가 어떤 선호 인덱스의 영향을 받냐에 따라서도 Parameter 간의 우선 순위가 역전될 수 있다.
SQL2007. 4. 16. 10:18
출처 : sqler.pe.kr
1.ALL_ROWS
Goal : Best Throughput
용도 : 전체 RESOURCE 소비를 최소화 시키기 위한 힌트.
Cost-Based 접근방식.
예 : SELECT /*+ALL_ROWS */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
2.FIRST_ROWS
Goal : Best Response Time
용도 : 조건에 맞는 첫번째 row를 리턴하기 위한 Resource
소비를 최소화 시키기위한 힌트.
Cost-Based 접근방식.
특징 : - Index Scan 이 가능하다면 Optimizer가 Full Table Scan 대신
Index Scan을 선택한다.
- Index Scan 이 가능하다면 Optimizer가 Sort-Merge 보다
Nested Loop 을 선택한다.
- Order By절에의해 Index Scan 이 가능하다면,
Sort과정을 피하기위해 Index Scan을 선택한다.
- Delete/Update Block 에서는 무시된다.
- 다음을 포함한 Select 문에서도 제외된다.
집합연산자 (Union,Intersect,Minus,Union All)
Group By
For UpDate
Group 함수
Distinct
예 : SELECT /*+FIRST_ROWS */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
3.CHOOSE
Goal : Acess되는 테이블에 통계치 존재여부에 따라
Optimizer로 하여금 Rule-Based Approach와 Cost-Based Approach
중 하나를 선택할수 있게 한다.
용도 : Data Dictionary가 해당테이블에 대해 통계정보를 가지고 있다면
Optimizer는 Cost-Based Approach를 선택하고,
그렇지 않다면 Rule-Based Approach를 선택한다.
예 : SELECT /*+CHOOSE */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
4.RULE
용도 : Rule-Based 최적화를 사용하기위해.
예 : SELECT /*+RULE */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
B. Access Methods 로써의 Hints
1.FULL
용도 : 해당테이블의 Full Table Scan을 유도.
예 : SELECT /*+FULL(EMP) */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
* 테이블 Alias 가 있는경우는 Alias사용.
Schema Name은 사용안함(From 에 SCOTT.EMP 라고 기술해도 hint에는 EMP사용).
2.ROWID
용도 : 지정된 테이블의 ROWID를 이용한 Scan 유도
3.CLUSTER
용도 : 지정된 테이블Access에 Cluster Scan 유도.
Cluster된 Objects에만 적용가능.
예 : SELECT /*+CLUSTER(EMP) */ ENAME,DEPTNO
FROM EMP,DEPT
WHERE DEPTNO = 10
AND EMP.DEPTNO = DEPT.DEPTNO;
4.HASH
용도 : 지정된 테이블Access에 HASH Scan 유도.
/*+HASH(table) */
5.HASH_AJ
용도 : NOT IN SubQuery 를 HASH anti-join으로 변형
/*+HASH_AJ */
6.HASH_SJ
용도 : correlated Exists SubQuery 를 HASH semi-join으로 변형
/*+HASH_SJ */
7.INDEX
용도 : 지정된 테이블Access에 Index Scan 유도.
* 하나의 index만 지정되면 optimizer는 해당index를 이용.
* 여러개의 인덱스가 지정되면 optimizer가 각 index의
scan시 cost를 분석 한 후 최소비용이 드는 index사용.
경우에 따라 optimizer는 여러 index를 사용한 후 결과를
merge하는 acees방식도 선택.
* index가 지정되지 않으면 optimizer는 테이블의 이용가능한
모든 index에 대해 scan cost를 고려후 최저비용이 드는
index scan을 선택한다.
예 : SELECT /*+INDEX(EMP EMPNO_INDEX) */ EMPNO,ENAME
FROM EMP
WHERE DEPTNO=10
8.INDEX_ASC
용도 : INDEX HINT와 동일 단,ASCENDING 으로 SCAN함을 확실히 하기위함.
9.INDEX_COMBINE
용도 : INDEX명이 주어지지 않으면 OPTIMIZER는 해당 테이블의
best cost 로 선택된 Boolean combination index 를 사용한다.
index 명이 주어지면 주어진 특정 bitmap index 의
boolean combination 의 사용을 시도한다.
/*+INDEX_COMBINE(table index) */
10.INDEX_DESC
용도 : 지정된 테이블의 지정된 index를 이용 descending으로 scan
하고자할때 사용.
/*+INDEX_DESC(table index) */
11.INDEX_FFS
용도 : full table scan보다 빠른 full index scan을 유도.
/*+INDEX_FFS(table index) */
12.MERGE_AJ
용도 : not in subquery를 merge anti-join으로 변형
/*+MERGE_AJ */
13.MERGE_SJ
용도 : correalted EXISTS subquery를 merge semi-join으로 변형
/*+MERGE_SJ */
14.AND_EQUAL
용도 : single-column index의 merge를 이용한 access path 선택.
적어도 두개이상의 index가 지정되어야한다.
/*+AND_EQUAL(table index1,index2...) */
15.USE_CONCAT
용도 : 조건절의 OR 를 Union ALL 형식으로 변형한다.
일반적으로 변형은 비용측면에서 효율적일때만 일어난다.
/*+USE_CONCAT */
C. JOIN 순서를 결정하는 Hints
1.ORDERED
용도 : from절에 기술된 테이블 순서대로 join이 일어나도록 유도.
/*+ORDERED */
예 : SELECT /*+ORDERED */ TAB1.COL1,TAB2.COL2,TAB3.COL3
FROM TAB1,TAB2,TAB3
WHERE TAB1.COL1=TAB2.COL1
AND TAB2.COL1=TAB3.COL1;
2.STAR
용도 : STAR QUERY PLAN이 사용가능하다면 이를 이용하기위한 HINT.
STAR PLAN은 규모가 가장큰 테이블이 QUERY에서 JOIN ORDER상
마지막으로 위치하게 하고 NESTED LOOP 으로 JOIN이 일어나도록
유도한다.
적어도 3개 테이블 이상이 조인에 참여해야하며 LARGE TABLE의
CONCATENATED INDEX는 최소 3컬럼 이상을 INDEX에 포함해야한다.
테이블이 ANALYZE 되어 있다면 OPTIMIZER가 가장효율적인 STAR PLAN을
선택한다.
/*+STAR */
D. JOIN OPERATION을 결정하는 HINTS.
1.USE_NL
용도 : 테이블의 JOIN 시 테이블의 각 ROW가 INNER 테이블을 NESTED LOOP
형식으로 JOIN 한다.
/*+USE_NL(inner_table) */
예 : SELECT /*+ORDERD USE_NL(CUSTOMER) */
FROM ACCOUNT.BALANCE,CUSTOMER.LAST_NAME,CUSTOMER.FIRST_NAME
WHERE ACCOUNT.CUSTNO = CUSTOMER.CUSTNO;
2.USE_MERGE
용도 : 지정된 테이블들의 조인이 SORT-MERGE형식으로 일어나도록 유도.
/*+USE_MERGE(table) */
* 괄호안의 테이블은 JOIN ORDER상의 뒤의 테이블(?)
3.USE_HASH
용도 : 각 테이블간 HASH JOIN이 일어나도록 유도.
/*+USE_HASH(table) */
* 괄호안의 테이블은 JOIN ORDER상의 뒤의 테이블(?)
4.DRIVING_SITE
용도 : QUERY의 실행이 ORACLE에 의해 선택된 SITE가 아닌 다른 SITE에서
일어나도록 유도.
/*+DRIVING_SITE(table) */
예 : SELECT /*+DRIVING_SITE(DEPT) */
FROM EMP,DEPT@RSITE
WHERE EMP.DEPTNO = DEPT.DEPTNO;
DRIVING_SITE 힌트를 안쓰면 DEPT의 ROW가 LOCAL SITE로 보내져
LOCAL SITE에서 JOIN이 일어나지만,
DRIVING_SITE 힌트를 쓰면 EMP의 ROW들이REMOTE SITE로 보내져
QUERY가 실행된후 LOCAL SITE로 결과가 RETURN된다.
1.ALL_ROWS
Goal : Best Throughput
용도 : 전체 RESOURCE 소비를 최소화 시키기 위한 힌트.
Cost-Based 접근방식.
예 : SELECT /*+ALL_ROWS */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
2.FIRST_ROWS
Goal : Best Response Time
용도 : 조건에 맞는 첫번째 row를 리턴하기 위한 Resource
소비를 최소화 시키기위한 힌트.
Cost-Based 접근방식.
특징 : - Index Scan 이 가능하다면 Optimizer가 Full Table Scan 대신
Index Scan을 선택한다.
- Index Scan 이 가능하다면 Optimizer가 Sort-Merge 보다
Nested Loop 을 선택한다.
- Order By절에의해 Index Scan 이 가능하다면,
Sort과정을 피하기위해 Index Scan을 선택한다.
- Delete/Update Block 에서는 무시된다.
- 다음을 포함한 Select 문에서도 제외된다.
집합연산자 (Union,Intersect,Minus,Union All)
Group By
For UpDate
Group 함수
Distinct
예 : SELECT /*+FIRST_ROWS */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
3.CHOOSE
Goal : Acess되는 테이블에 통계치 존재여부에 따라
Optimizer로 하여금 Rule-Based Approach와 Cost-Based Approach
중 하나를 선택할수 있게 한다.
용도 : Data Dictionary가 해당테이블에 대해 통계정보를 가지고 있다면
Optimizer는 Cost-Based Approach를 선택하고,
그렇지 않다면 Rule-Based Approach를 선택한다.
예 : SELECT /*+CHOOSE */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
4.RULE
용도 : Rule-Based 최적화를 사용하기위해.
예 : SELECT /*+RULE */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
B. Access Methods 로써의 Hints
1.FULL
용도 : 해당테이블의 Full Table Scan을 유도.
예 : SELECT /*+FULL(EMP) */ EMPNO,ENAME
FROM EMP
WHERE EMPNO = 7655;
* 테이블 Alias 가 있는경우는 Alias사용.
Schema Name은 사용안함(From 에 SCOTT.EMP 라고 기술해도 hint에는 EMP사용).
2.ROWID
용도 : 지정된 테이블의 ROWID를 이용한 Scan 유도
3.CLUSTER
용도 : 지정된 테이블Access에 Cluster Scan 유도.
Cluster된 Objects에만 적용가능.
예 : SELECT /*+CLUSTER(EMP) */ ENAME,DEPTNO
FROM EMP,DEPT
WHERE DEPTNO = 10
AND EMP.DEPTNO = DEPT.DEPTNO;
4.HASH
용도 : 지정된 테이블Access에 HASH Scan 유도.
/*+HASH(table) */
5.HASH_AJ
용도 : NOT IN SubQuery 를 HASH anti-join으로 변형
/*+HASH_AJ */
6.HASH_SJ
용도 : correlated Exists SubQuery 를 HASH semi-join으로 변형
/*+HASH_SJ */
7.INDEX
용도 : 지정된 테이블Access에 Index Scan 유도.
* 하나의 index만 지정되면 optimizer는 해당index를 이용.
* 여러개의 인덱스가 지정되면 optimizer가 각 index의
scan시 cost를 분석 한 후 최소비용이 드는 index사용.
경우에 따라 optimizer는 여러 index를 사용한 후 결과를
merge하는 acees방식도 선택.
* index가 지정되지 않으면 optimizer는 테이블의 이용가능한
모든 index에 대해 scan cost를 고려후 최저비용이 드는
index scan을 선택한다.
예 : SELECT /*+INDEX(EMP EMPNO_INDEX) */ EMPNO,ENAME
FROM EMP
WHERE DEPTNO=10
8.INDEX_ASC
용도 : INDEX HINT와 동일 단,ASCENDING 으로 SCAN함을 확실히 하기위함.
9.INDEX_COMBINE
용도 : INDEX명이 주어지지 않으면 OPTIMIZER는 해당 테이블의
best cost 로 선택된 Boolean combination index 를 사용한다.
index 명이 주어지면 주어진 특정 bitmap index 의
boolean combination 의 사용을 시도한다.
/*+INDEX_COMBINE(table index) */
10.INDEX_DESC
용도 : 지정된 테이블의 지정된 index를 이용 descending으로 scan
하고자할때 사용.
/*+INDEX_DESC(table index) */
11.INDEX_FFS
용도 : full table scan보다 빠른 full index scan을 유도.
/*+INDEX_FFS(table index) */
12.MERGE_AJ
용도 : not in subquery를 merge anti-join으로 변형
/*+MERGE_AJ */
13.MERGE_SJ
용도 : correalted EXISTS subquery를 merge semi-join으로 변형
/*+MERGE_SJ */
14.AND_EQUAL
용도 : single-column index의 merge를 이용한 access path 선택.
적어도 두개이상의 index가 지정되어야한다.
/*+AND_EQUAL(table index1,index2...) */
15.USE_CONCAT
용도 : 조건절의 OR 를 Union ALL 형식으로 변형한다.
일반적으로 변형은 비용측면에서 효율적일때만 일어난다.
/*+USE_CONCAT */
C. JOIN 순서를 결정하는 Hints
1.ORDERED
용도 : from절에 기술된 테이블 순서대로 join이 일어나도록 유도.
/*+ORDERED */
예 : SELECT /*+ORDERED */ TAB1.COL1,TAB2.COL2,TAB3.COL3
FROM TAB1,TAB2,TAB3
WHERE TAB1.COL1=TAB2.COL1
AND TAB2.COL1=TAB3.COL1;
2.STAR
용도 : STAR QUERY PLAN이 사용가능하다면 이를 이용하기위한 HINT.
STAR PLAN은 규모가 가장큰 테이블이 QUERY에서 JOIN ORDER상
마지막으로 위치하게 하고 NESTED LOOP 으로 JOIN이 일어나도록
유도한다.
적어도 3개 테이블 이상이 조인에 참여해야하며 LARGE TABLE의
CONCATENATED INDEX는 최소 3컬럼 이상을 INDEX에 포함해야한다.
테이블이 ANALYZE 되어 있다면 OPTIMIZER가 가장효율적인 STAR PLAN을
선택한다.
/*+STAR */
D. JOIN OPERATION을 결정하는 HINTS.
1.USE_NL
용도 : 테이블의 JOIN 시 테이블의 각 ROW가 INNER 테이블을 NESTED LOOP
형식으로 JOIN 한다.
/*+USE_NL(inner_table) */
예 : SELECT /*+ORDERD USE_NL(CUSTOMER) */
FROM ACCOUNT.BALANCE,CUSTOMER.LAST_NAME,CUSTOMER.FIRST_NAME
WHERE ACCOUNT.CUSTNO = CUSTOMER.CUSTNO;
2.USE_MERGE
용도 : 지정된 테이블들의 조인이 SORT-MERGE형식으로 일어나도록 유도.
/*+USE_MERGE(table) */
* 괄호안의 테이블은 JOIN ORDER상의 뒤의 테이블(?)
3.USE_HASH
용도 : 각 테이블간 HASH JOIN이 일어나도록 유도.
/*+USE_HASH(table) */
* 괄호안의 테이블은 JOIN ORDER상의 뒤의 테이블(?)
4.DRIVING_SITE
용도 : QUERY의 실행이 ORACLE에 의해 선택된 SITE가 아닌 다른 SITE에서
일어나도록 유도.
/*+DRIVING_SITE(table) */
예 : SELECT /*+DRIVING_SITE(DEPT) */
FROM EMP,DEPT@RSITE
WHERE EMP.DEPTNO = DEPT.DEPTNO;
DRIVING_SITE 힌트를 안쓰면 DEPT의 ROW가 LOCAL SITE로 보내져
LOCAL SITE에서 JOIN이 일어나지만,
DRIVING_SITE 힌트를 쓰면 EMP의 ROW들이REMOTE SITE로 보내져
QUERY가 실행된후 LOCAL SITE로 결과가 RETURN된다.
SQL2007. 4. 6. 16:35
Forms2007. 4. 6. 13:23

